
Host Protein General Information
| Protein Name |
Collagen alpha-3(VI) chain
|
Gene Name |
COL6A3
|
||||||
|---|---|---|---|---|---|---|---|---|---|
| Host Species |
Homo sapiens
|
Uniprot Entry Name |
CO6A3_HUMAN
|
||||||
| Protein Families |
Type VI collagen family
|
||||||||
| Subcellular Location |
Secreted; extracellular matrix
|
||||||||
| External Link | |||||||||
| NCBI Gene ID | |||||||||
| Uniprot ID | |||||||||
| Ensembl ID | |||||||||
| HGNC ID | |||||||||
| Related KEGG Pathway | |||||||||
| Human papillomavirus infection | hsa05165 |
Pathway Map 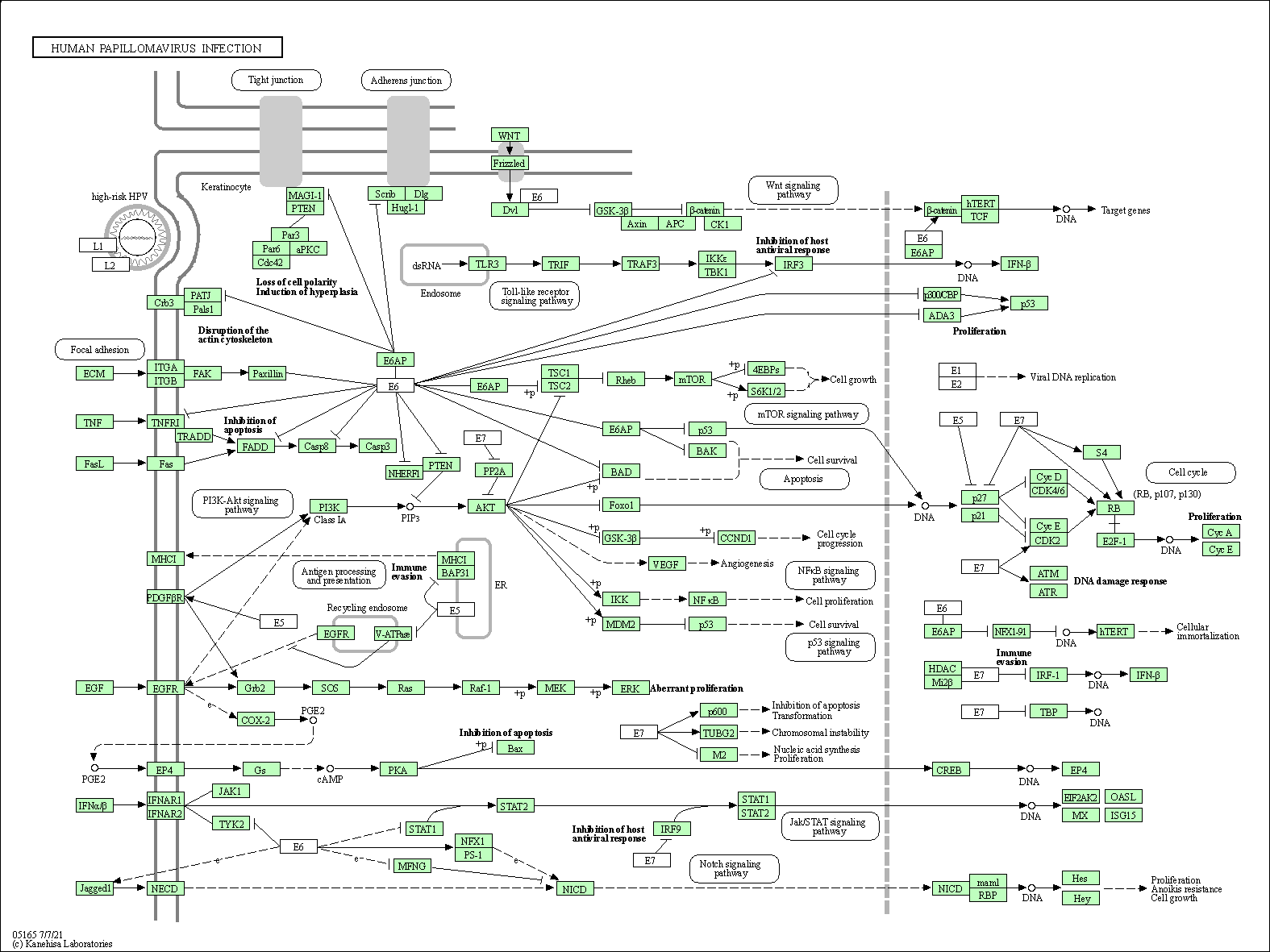
|
|||||||
| Focal adhesion | hsa04510 |
Pathway Map 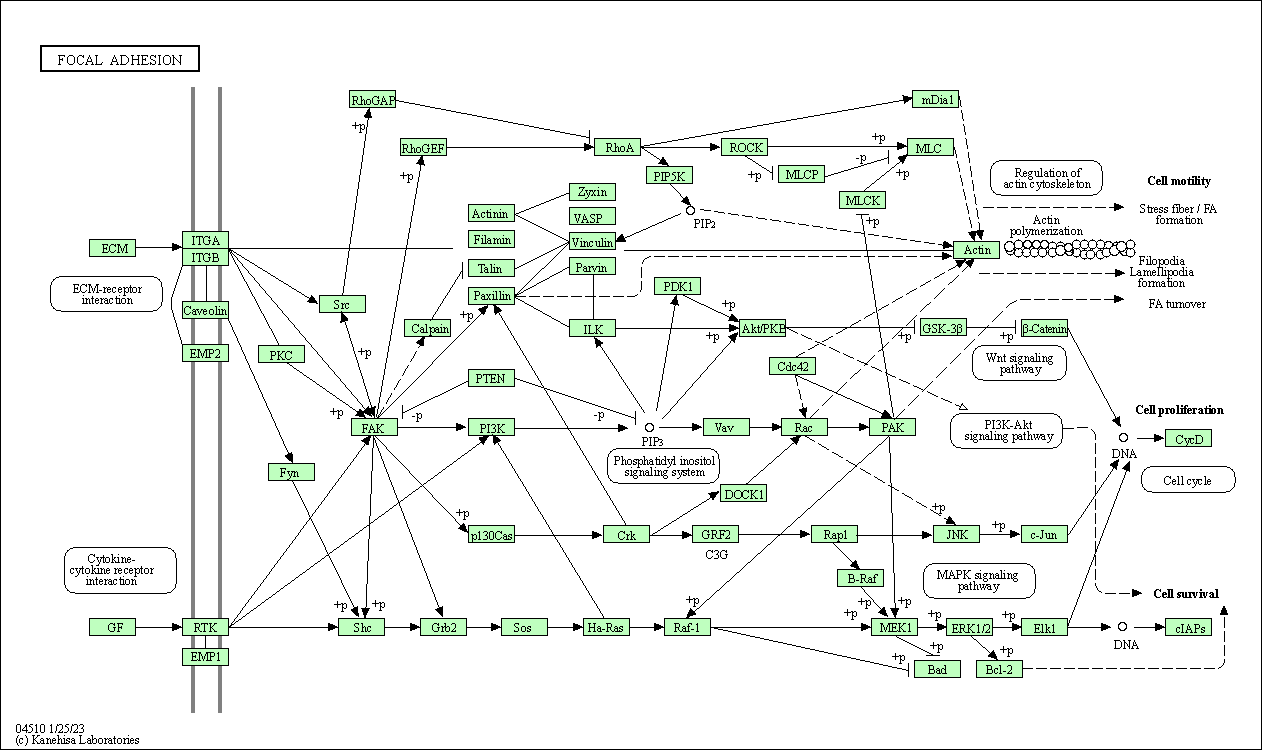
|
|||||||
| Protein digestion and absorption | hsa04974 |
Pathway Map 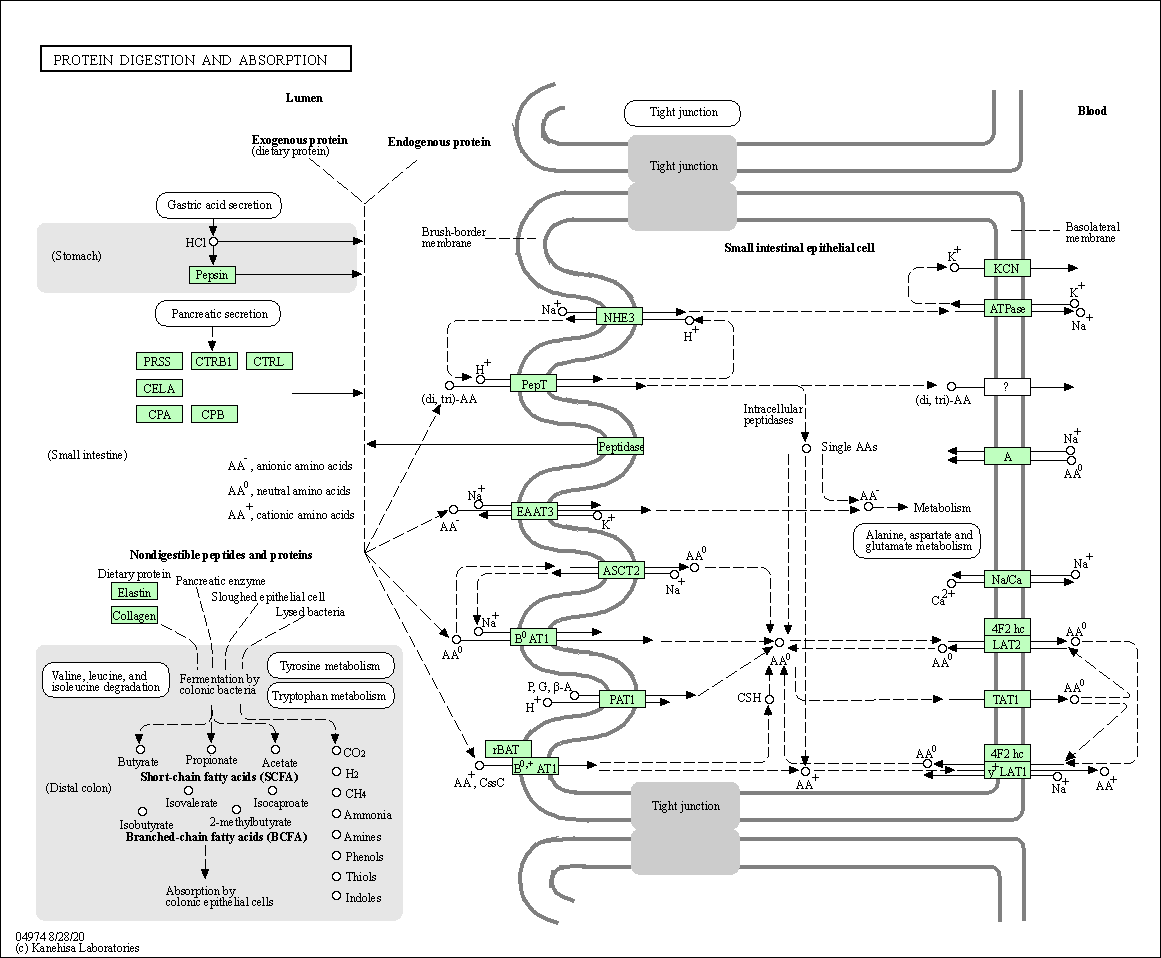
|
|||||||
| PI3K-Akt signaling pathway | hsa04151 |
Pathway Map 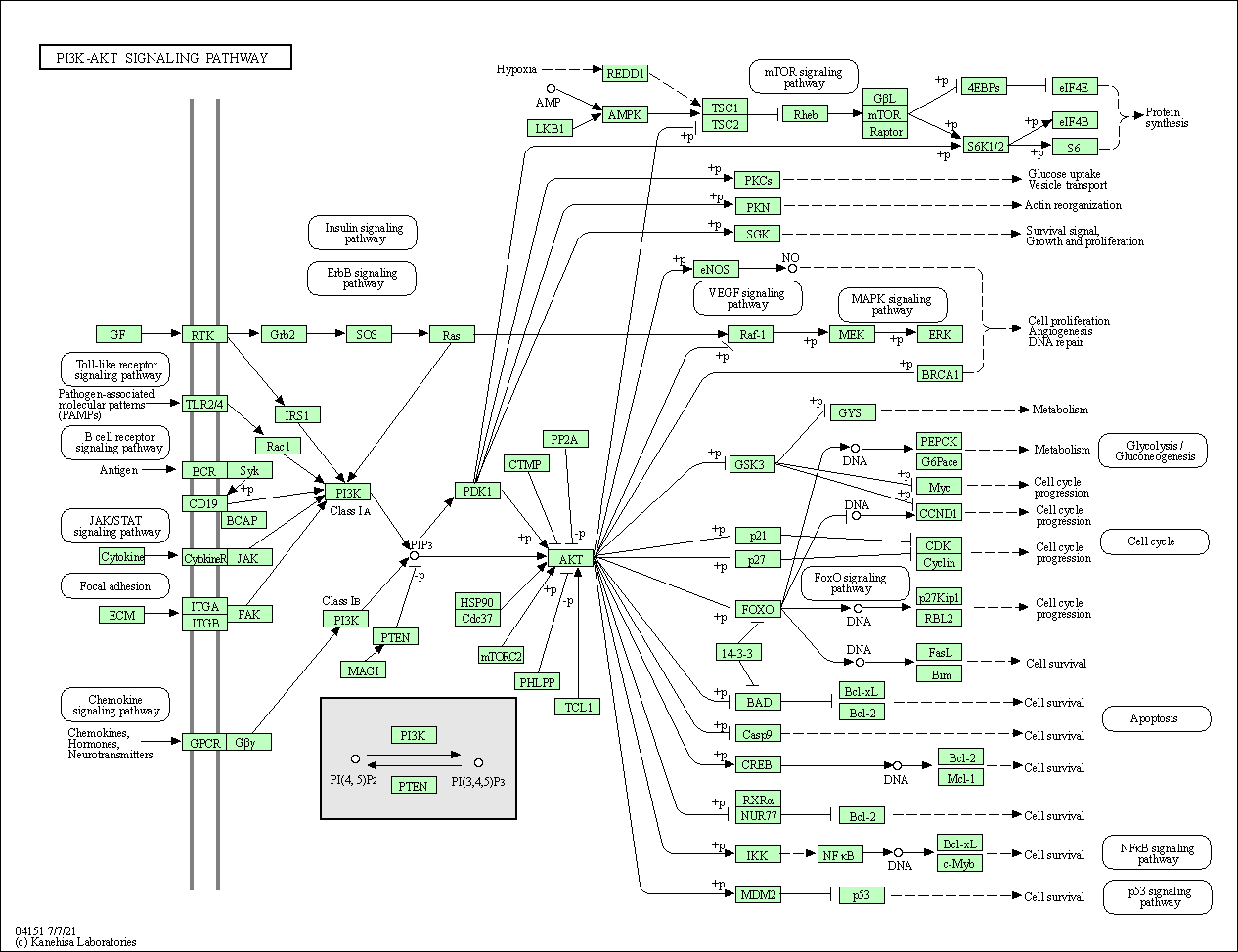
|
|||||||
| ECM-receptor interaction | hsa04512 |
Pathway Map 
|
|||||||
| 3D Structure |
|
||||||||
Full List of Virus RNA Interacting with This Protien
| Virus Name | Binding Region | RNA Info | Detection Method | Infection Cell | Cell ID | Cell Originated Tissue | Infection Time | Interaction Score 1 | Interaction Score 2 |
|---|---|---|---|---|---|---|---|---|---|
| Chikungunya virus (strain 181/25) | 5'UTR - 3'UTR | RNA Info | VIRal Cross-Linking And Solid-phase Purification (VIR-CLASP) | BHK-21 Cells (Small hamster kidney fibroblast) | . | Kidney | 3 h | . | . |
| Chikungunya virus (strain 181/25) | 5'UTR - 3'UTR | RNA Info | VIRal Cross-Linking And Solid-phase Purification (VIR-CLASP) | BHK-21 Cells (Small hamster kidney fibroblast) | . | Kidney | 0.2 h | . | . |
Potential Drug(s) that Targets This Protein
| Drug Name | DrunkBank ID | Pubchem ID | TTD ID | REF | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| COLLAGENASE CLOSTRIDIUM HISTOLYTICUM | . | ? | D0I4ZQ | DGIdb | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OCRIPLASMIN | . | ? | D0Y7XG | DGIdb | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Protein Sequence Information
|
MRKHRHLPLVAVFCLFLSGFPTTHAQQQQADVKNGAAADIIFLVDSSWTIGEEHFQLVREFLYDVVKSLAVGENDFHFALVQFNGNPHTEFLLNTYRTKQEVLSHISNMSYIGGTNQTGKGLEYIMQSHLTKAAGSRAGDGVPQVIVVLTDGHSKDGLALPSAELKSADVNVFAIGVEDADEGALKEIASEPLNMHMFNLENFTSLHDIVGNLVSCVHSSVSPERAGDTETLKDITAQDSADIIFLIDGSNNTGSVNFAVILDFLVNLLEKLPIGTQQIRVGVVQFSDEPRTMFSLDTYSTKAQVLGAVKALGFAGGELANIGLALDFVVENHFTRAGGSRVEEGVPQVLVLISAGPSSDEIRYGVVALKQASVFSFGLGAQAASRAELQHIATDDNLVFTVPEFRSFGDLQEKLLPYIVGVAQRHIVLKPPTIVTQVIEVNKRDIVFLVDGSSALGLANFNAIRDFIAKVIQRLEIGQDLIQVAVAQYADTVRPEFYFNTHPTKREVITAVRKMKPLDGSALYTGSALDFVRNNLFTSSAGYRAAEGIPKLLVLITGGKSLDEISQPAQELKRSSIMAFAIGNKGADQAELEEIAFDSSLVFIPAEFRAAPLQGMLPGLLAPLRTLSGTPEVHSNKRDIIFLLDGSANVGKTNFPYVRDFVMNLVNSLDIGNDNIRVGLVQFSDTPVTEFSLNTYQTKSDILGHLRQLQLQGGSGLNTGSALSYVYANHFTEAGGSRIREHVPQLLLLLTAGQSEDSYLQAANALTRAGILTFCVGASQANKAELEQIAFNPSLVYLMDDFSSLPALPQQLIQPLTTYVSGGVEEVPLAQPESKRDILFLFDGSANLVGQFPVVRDFLYKIIDELNVKPEGTRIAVAQYSDDVKVESRFDEHQSKPEILNLVKRMKIKTGKALNLGYALDYAQRYIFVKSAGSRIEDGVLQFLVLLVAGRSSDRVDGPASNLKQSGVVPFIFQAKNADPAELEQIVLSPAFILAAESLPKIGDLHPQIVNLLKSVHNGAPAPVSGEKDVVFLLDGSEGVRSGFPLLKEFVQRVVESLDVGQDRVRVAVVQYSDRTRPEFYLNSYMNKQDVVNAVRQLTLLGGPTPNTGAALEFVLRNILVSSAGSRITEGVPQLLIVLTADRSGDDVRNPSVVVKRGGAVPIGIGIGNADITEMQTISFIPDFAVAIPTFRQLGTVQQVISERVTQLTREELSRLQPVLQPLPSPGVGGKRDVVFLIDGSQSAGPEFQYVRTLIERLVDYLDVGFDTTRVAVIQFSDDPKVEFLLNAHSSKDEVQNAVQRLRPKGGRQINVGNALEYVSRNIFKRPLGSRIEEGVPQFLVLISSGKSDDEVDDPAVELKQFGVAPFTIARNADQEELVKISLSPEYVFSVSTFRELPSLEQKLLTPITTLTSEQIQKLLASTRYPPPAVESDAADIVFLIDSSEGVRPDGFAHIRDFVSRIVRRLNIGPSKVRVGVVQFSNDVFPEFYLKTYRSQAPVLDAIRRLRLRGGSPLNTGKALEFVARNLFVKSAGSRIEDGVPQHLVLVLGGKSQDDVSRFAQVIRSSGIVSLGVGDRNIDRTELQTITNDPRLVFTVREFRELPNIEERIMNSFGPSAATPAPPGVDTPPPSRPEKKKADIVFLLDGSINFRRDSFQEVLRFVSEIVDTVYEDGDSIQVGLVQYNSDPTDEFFLKDFSTKRQIIDAINKVVYKGGRHANTKVGLEHLRVNHFVPEAGSRLDQRVPQIAFVITGGKSVEDAQDVSLALTQRGVKVFAVGVRNIDSEEVGKIASNSATAFRVGNVQELSELSEQVLETLHDAMHETLCPGVTDAAKACNLDVILGFDGSRDQNVFVAQKGFESKVDAILNRISQMHRVSCSGGRSPTVRVSVVANTPSGPVEAFDFDEYQPEMLEKFRNMRSQHPYVLTEDTLKVYLNKFRQSSPDSVKVVIHFTDGADGDLADLHRASENLRQEGVRALILVGLERVVNLERLMHLEFGRGFMYDRPLRLNLLDLDYELAEQLDNIAEKACCGVPCKCSGQRGDRGPIGSIGPKGIPGEDGYRGYPGDEGGPGERGPPGVNGTQGFQGCPGQRGVKGSRGFPGEKGEVGEIGLDGLDGEDGDKGLPGSSGEKGNPGRRGDKGPRGEKGERGDVGIRGDPGNPGQDSQERGPKGETGDLGPMGVPGRDGVPGGPGETGKNGGFGRRGPPGAKGNKGGPGQPGFEGEQGTRGAQGPAGPAGPPGLIGEQGISGPRGSGGAAGAPGERGRTGPLGRKGEPGEPGPKGGIGNRGPRGETGDDGRDGVGSEGRRGKKGERGFPGYPGPKGNPGEPGLNGTTGPKGIRGRRGNSGPPGIVGQKGDPGYPGPAGPKGNRGDSIDQCALIQSIKDKCPCCYGPLECPVFPTELAFALDTSEGVNQDTFGRMRDVVLSIVNDLTIAESNCPRGARVAVVTYNNEVTTEIRFADSKRKSVLLDKIKNLQVALTSKQQSLETAMSFVARNTFKRVRNGFLMRKVAVFFSNTPTRASPQLREAVLKLSDAGITPLFLTRQEDRQLINALQINNTAVGHALVLPAGRDLTDFLENVLTCHVCLDICNIDPSCGFGSWRPSFRDRRAAGSDVDIDMAFILDSAETTTLFQFNEMKKYIAYLVRQLDMSPDPKASQHFARVAVVQHAPSESVDNASMPPVKVEFSLTDYGSKEKLVDFLSRGMTQLQGTRALGSAIEYTIENVFESAPNPRDLKIVVLMLTGEVPEQQLEEAQRVILQAKCKGYFFVVLGIGRKVNIKEVYTFASEPNDVFFKLVDKSTELNEEPLMRFGRLLPSFVSSENAFYLSPDIRKQCDWFQGDQPTKNLVKFGHKQVNVPNNVTSSPTSNPVTTTKPVTTTKPVTTTTKPVTTTTKPVTIINQPSVKPAAAKPAPAKPVAAKPVATKMATVRPPVAVKPATAAKPVAAKPAAVRPPAAAAAKPVATKPEVPRPQAAKPAATKPATTKPMVKMSREVQVFEITENSAKLHWERAEPPGPYFYDLTVTSAHDQSLVLKQNLTVTDRVIGGLLAGQTYHVAVVCYLRSQVRATYHGSFSTKKSQPPPPQPARSASSSTINLMVSTEPLALTETDICKLPKDEGTCRDFILKWYYDPNTKSCARFWYGGCGGNENKFGSQKECEKVCAPVLAKPGVISVMGT
Click to Show/Hide
|