
Host Protein General Information
| Protein Name |
DOT1-like protein
|
Gene Name |
DOT1L
|
||||||
|---|---|---|---|---|---|---|---|---|---|
| Host Species |
Homo sapiens
|
Uniprot Entry Name |
DOT1L_HUMAN
|
||||||
| Protein Families |
Class I-like SAM-binding methyltransferase superfamily, DOT1 family
|
||||||||
| EC Number |
2.1.1.360
|
||||||||
| Subcellular Location |
Nucleus
|
||||||||
| External Link | |||||||||
| NCBI Gene ID | |||||||||
| Uniprot ID | |||||||||
| Ensembl ID | |||||||||
| HGNC ID | |||||||||
| Related KEGG Pathway | |||||||||
| Lysine degradation | hsa00310 |
Pathway Map 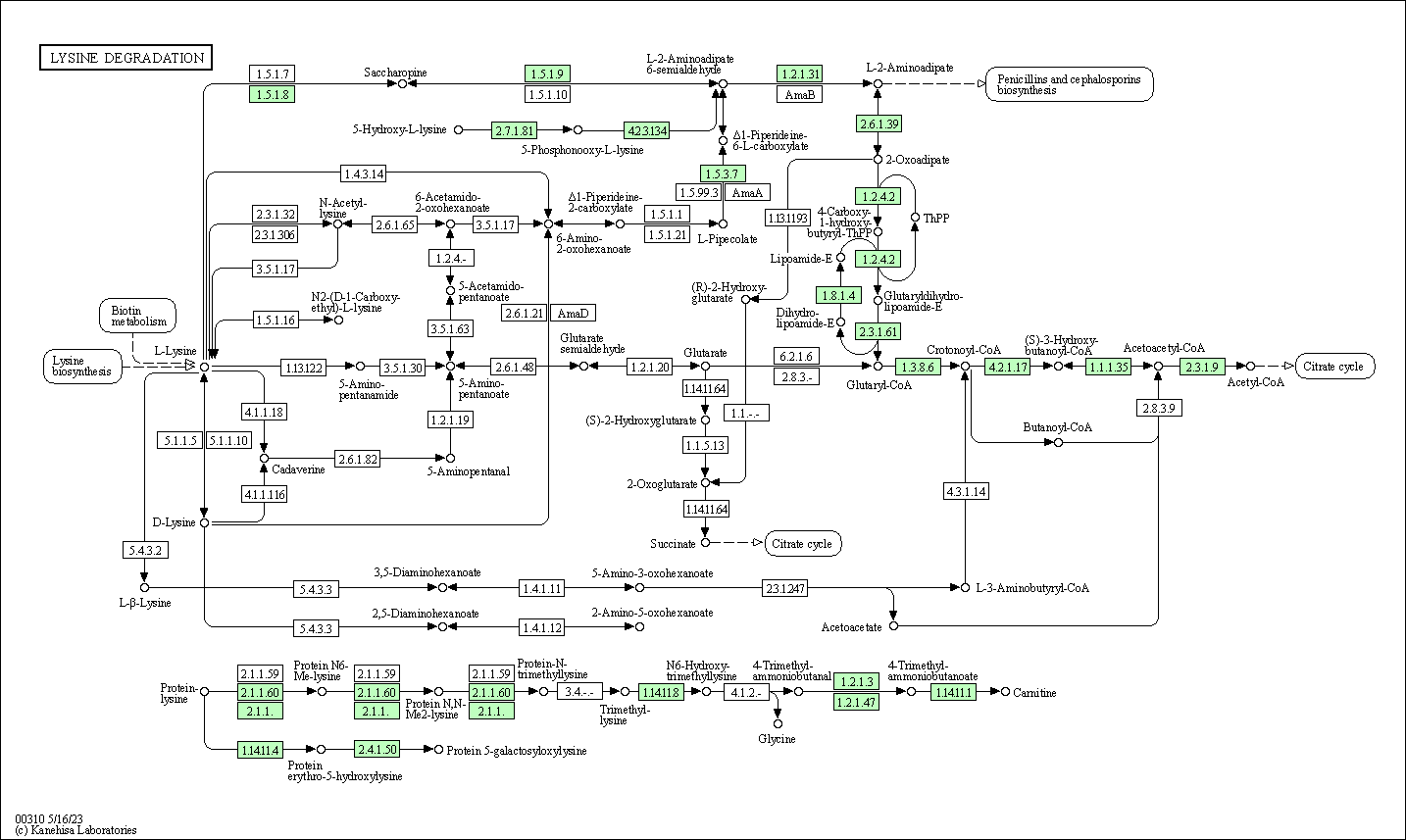
|
|||||||
| Transcriptional misregulation in cancer | hsa05202 |
Pathway Map 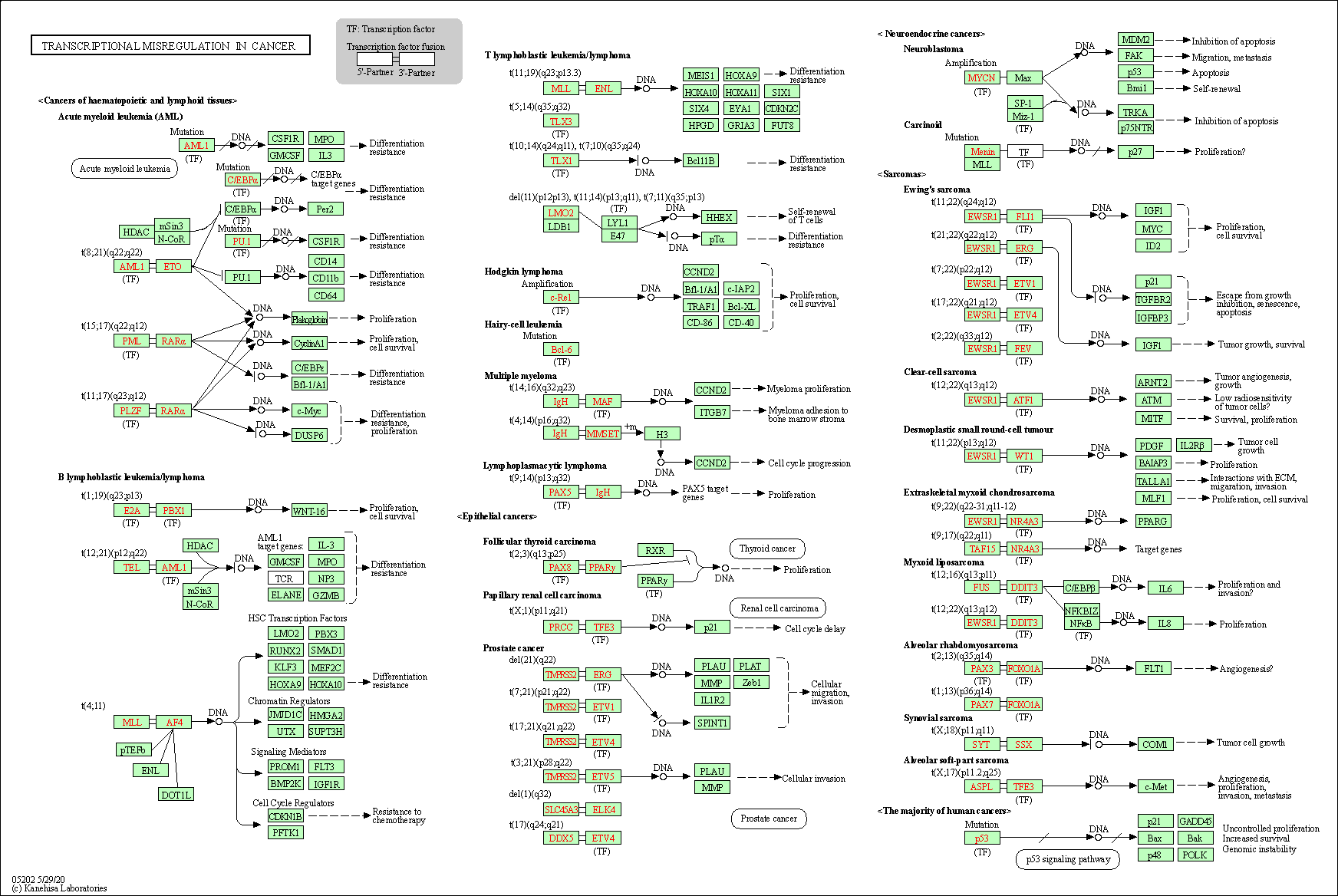
|
|||||||
| Metabolic pathways | hsa01100 |
Pathway Map 
|
|||||||
| 3D Structure |
|
||||||||
Full List of Virus RNA Interacting with This Protien
| Virus Name | Binding Region | RNA Info | Detection Method | Infection Cell | Cell ID | Cell Originated Tissue | Infection Time | Interaction Score 1 | Interaction Score 2 |
|---|---|---|---|---|---|---|---|---|---|
| Dengue virus 2 (strain NGC) | 5'UTR - 3'UTR | RNA Info | VIRal Cross-Linking And Solid-phase Purification (VIR-CLASP) | HuH-7 Cells (Human hepatocellular carcinoma cell) | . | Liver | . | . | . |
Potential Drug(s) that Targets This Protein
| Drug Name | DrunkBank ID | Pubchem ID | TTD ID | REF | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| adenosine | . | 60961 | D06IAR | DrugCentral | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| CANDESARTAN | . | 2541 | D0D5SQ | DGIdb | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| HYDROCHLOROTHIAZIDE | . | 3639 | D0U4UQ | DGIdb | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PINOMETOSTAT | . | 57345410 | D0C6GK | DGIdb | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Protein Sequence Information
|
MGEKLELRLKSPVGAEPAVYPWPLPVYDKHHDAAHEIIETIRWVCEEIPDLKLAMENYVLIDYDTKSFESMQRLCDKYNRAIDSIHQLWKGTTQPMKLNTRPSTGLLRHILQQVYNHSVTDPEKLNNYEPFSPEVYGETSFDLVAQMIDEIKMTDDDLFVDLGSGVGQVVLQVAAATNCKHHYGVEKADIPAKYAETMDREFRKWMKWYGKKHAEYTLERGDFLSEEWRERIANTSVIFVNNFAFGPEVDHQLKERFANMKEGGRIVSSKPFAPLNFRINSRNLSDIGTIMRVVELSPLKGSVSWTGKPVSYYLHTIDRTILENYFSSLKNPKLREEQEAARRRQQRESKSNAATPTKGPEGKVAGPADAPMDSGAEEEKAGAATVKKPSPSKARKKKLNKKGRKMAGRKRGRPKKMNTANPERKPKKNQTALDALHAQTVSQTAASSPQDAYRSPHSPFYQLPPSVQRHSPNPLLVAPTPPALQKLLESFKIQYLQFLAYTKTPQYKASLQELLGQEKEKNAQLLGAAQQLLSHCQAQKEEIRRLFQQKLDELGVKALTYNDLIQAQKEISAHNQQLREQSEQLEQDNRALRGQSLQLLKARCEELQLDWATLSLEKLLKEKQALKSQISEKQRHCLELQISIVELEKSQRQQELLQLKSCVPPDDALSLHLRGKGALGRELEPDASRLHLELDCTKFSLPHLSSMSPELSMNGQAAGYELCGVLSRPSSKQNTPQYLASPLDQEVVPCTPSHVGRPRLEKLSGLAAPDYTRLSPAKIVLRRHLSQDHTVPGRPAASELHSRAEHTKENGLPYQSPSVPGSMKLSPQDPRPLSPGALQLAGEKSSEKGLRERAYGSSGELITSLPISIPLSTVQPNKLPVSIPLASVVLPSRAERARSTPSPVLQPRDPSSTLEKQIGANAHGAGSRSLALAPAGFSYAGSVAISGALAGSPASLTPGAEPATLDESSSSGSLFATVGSRSSTPQHPLLLAQPRNSLPASPAHQLSSSPRLGGAAQGPLPEASKGDLPSDSGFSDPESEAKRRIVFTITTGAGSAKQSPSSKHSPLTASARGDCVPSHGQDSRRRGRRKRASAGTPSLSAGVSPKRRALPSVAGLFTQPSGSPLNLNSMVSNINQPLEITAISSPETSLKSSPVPYQDHDQPPVLKKERPLSQTNGAHYSPLTSDEEPGSEDEPSSARIERKIATISLESKSPPKTLENGGGLAGRKPAPAGEPVNSSKWKSTFSPISDIGLAKSADSPLQASSALSQNSLFTFRPALEEPSADAKLAAHPRKGFPGSLSGADGLSPGTNPANGCTFGGGLAADLSLHSFSDGASLPHKGPEAAGLSSPLSFPSQRGKEGSDANPFLSKRQLDGLAGLKGEGSRGKEAGEGGLPLCGPTDKTPLLSGKAAKARDREVDLKNGHNLFISAAAVPPGSLLSGPGLAPAASSAGGAASSAQTHRSFLGPFPPGPQFALGPMSLQANLGSVAGSSVLQSLFSSVPAAAGLVHVSSAATRLTNSHAMGSFSGVAGGTVGGN
Click to Show/Hide
|